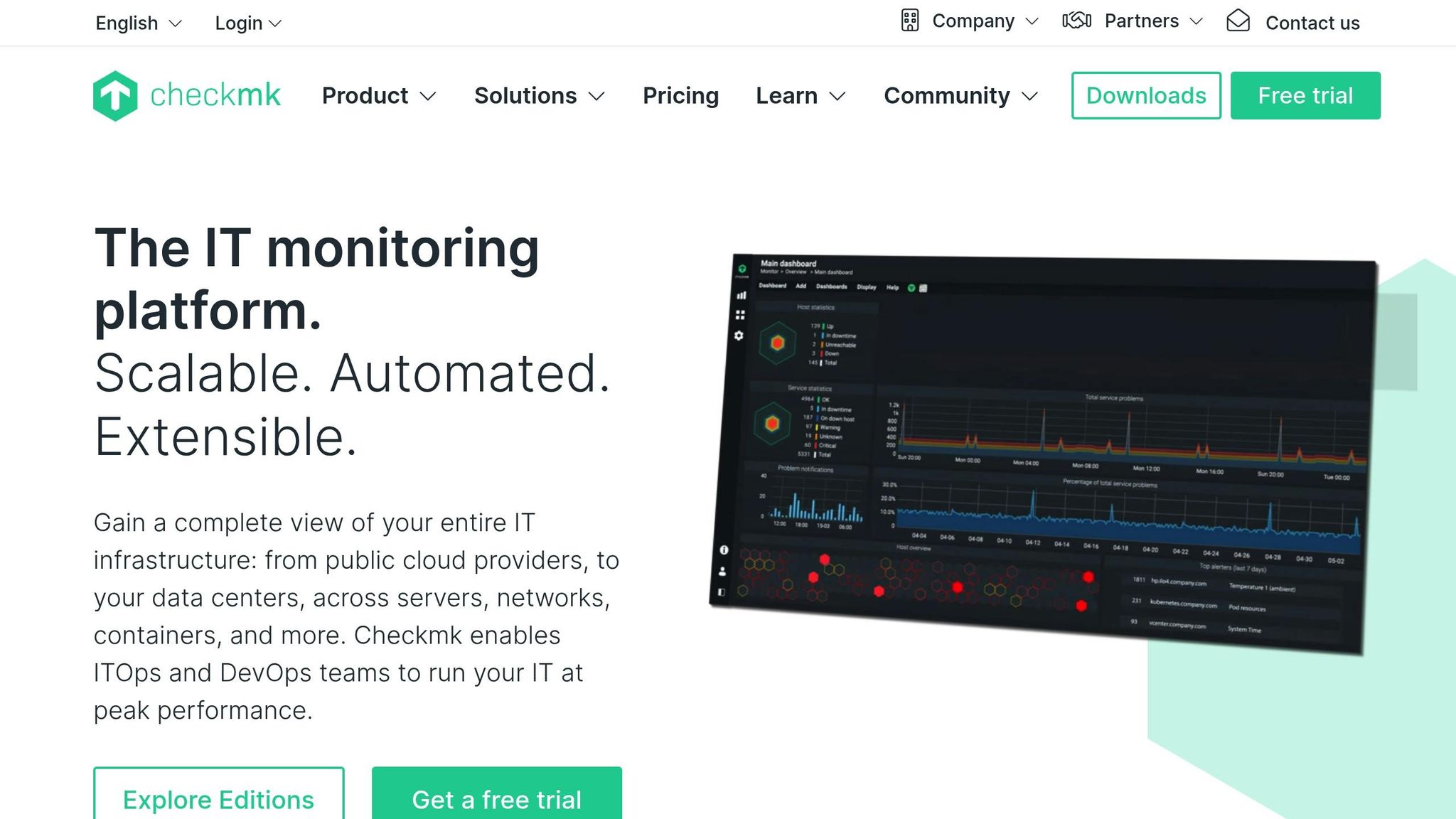
Portée de la surveillance
Checkmk couvre une large empreinte de surveillance, en suivant l'infrastructure, les réseaux, les applications, les conteneurs et les services cloud à partir d'une seule plateforme. Il offre des vérifications approfondies des hôtes et des services grâce à son vaste catalogue de plugins de surveillance, vous permettant d'observer la santé du matériel, les bases de données, les systèmes de stockage, les couches de virtualisation et les applications personnalisées. Il recueille des mesures détaillées à intervalles rapprochés et met en corrélation les changements d'état entre les systèmes afin de mettre en évidence les problèmes émergents. Sa conception hybride prend en charge la surveillance avec et sans agent, ce qui lui confère une grande souplesse pour les centres de données, les installations sur site et les environnements distribués.
Capacités en temps réel
Checkmk fournit des tableaux de bord en direct qui se mettent à jour continuellement, montrant les états des hôtes, les contrôles de service et les mesures de performance au fur et à mesure qu'ils changent. Il prend en charge l'interrogation rapide des hôtes critiques et peut afficher des graphiques en temps réel de la charge, de la mémoire, du réseau et de la santé des applications. Les tableaux de bord sont personnalisables, ce qui permet aux équipes de mettre en évidence les systèmes prioritaires et de détecter rapidement les problèmes urgents. Son noyau de surveillance efficace maintient les frais généraux à un niveau bas, même avec des milliers de vérifications par minute, ce qui permet aux grandes installations de maintenir une visibilité réactive en temps réel.
Fonctionnalités d'IA et d'automatisation
Checkmk comprend un réglage automatisé des seuils et un traitement intelligent des règles qui réduisent la fatigue des alertes en s'adaptant au comportement de base. Il peut découvrir automatiquement les hôtes et les services et appliquer des règles de surveillance prédéfinies sans configuration manuelle. Les fonctions prédictives prennent en charge l'analyse des tendances et la planification des capacités, aidant les équipes à repérer rapidement les risques de saturation. Pour les environnements complexes, son système d'automatisation basé sur des règles rationalise les mises à jour de configuration, l'activation des contrôles et la logique de notification. Les fonctions d'IA plus approfondies nécessitent généralement un couplage avec des outils d'analyse externes, car Checkmk se concentre sur la surveillance déterministe plutôt que sur l'automatisation complète des incidents.
Facilité de déploiement
Checkmk est simple à déployer grâce à un processus d'installation rapide et des guides d'installation clairs. L'édition brute utilise des composants open source, tandis que l'édition entreprise comprend une interface utilisateur raffinée et des améliorations de performance. Les agents peuvent être installés à l'aide d'un petit script, et la découverte automatique détecte immédiatement les nouveaux services. Il s'intègre bien aux environnements virtualisés et conteneurisés, et il évolue facilement grâce à des sites de surveillance distribués pour les déploiements de grande envergure ou multirégionaux. Parce qu'il offre de solides valeurs par défaut dès sa sortie de l'emballage, les équipes peuvent faire fonctionner rapidement un système de surveillance complet sans avoir à procéder à des réglages approfondis.
Tarifs
Checkmk propose une édition brute gratuite qui comprend la surveillance de base, les tableaux de bord et les alertes, ce qui la rend adaptée aux petites équipes ou aux environnements de laboratoire. L'édition entreprise ajoute des fonctionnalités avancées telles que de meilleures performances, une automatisation étendue, des analyses prédictives et des rapports à long terme. Le prix de l'édition entreprise est généralement basé sur le nombre d'hôtes surveillés, en commençant par un niveau d'entrée accessible et en évoluant pour les infrastructures plus importantes. Les coûts globaux restent ainsi prévisibles, ce qui est intéressant pour les organisations qui souhaitent disposer d'un système de surveillance puissant sans avoir à payer des frais d'utilisation élevés de type SaaS.