Alcance de la supervisión
Checkmk cubre una amplia huella de monitorización, rastreando infraestructuras, redes, aplicaciones, contenedores y servicios en la nube desde una única plataforma. Ofrece comprobaciones exhaustivas de hosts y servicios a través de su amplio catálogo de complementos de supervisión, que le permiten observar el estado del hardware, las bases de datos, los sistemas de almacenamiento, las capas de virtualización y las aplicaciones personalizadas. Recopila métricas detalladas a intervalos cortos y correlaciona los cambios de estado entre sistemas para poner de relieve los problemas emergentes. Su diseño híbrido admite tanto la supervisión basada en agentes como la que no lo está, lo que aporta flexibilidad en los centros de datos, las instalaciones locales y los entornos distribuidos.
Capacidades en tiempo real
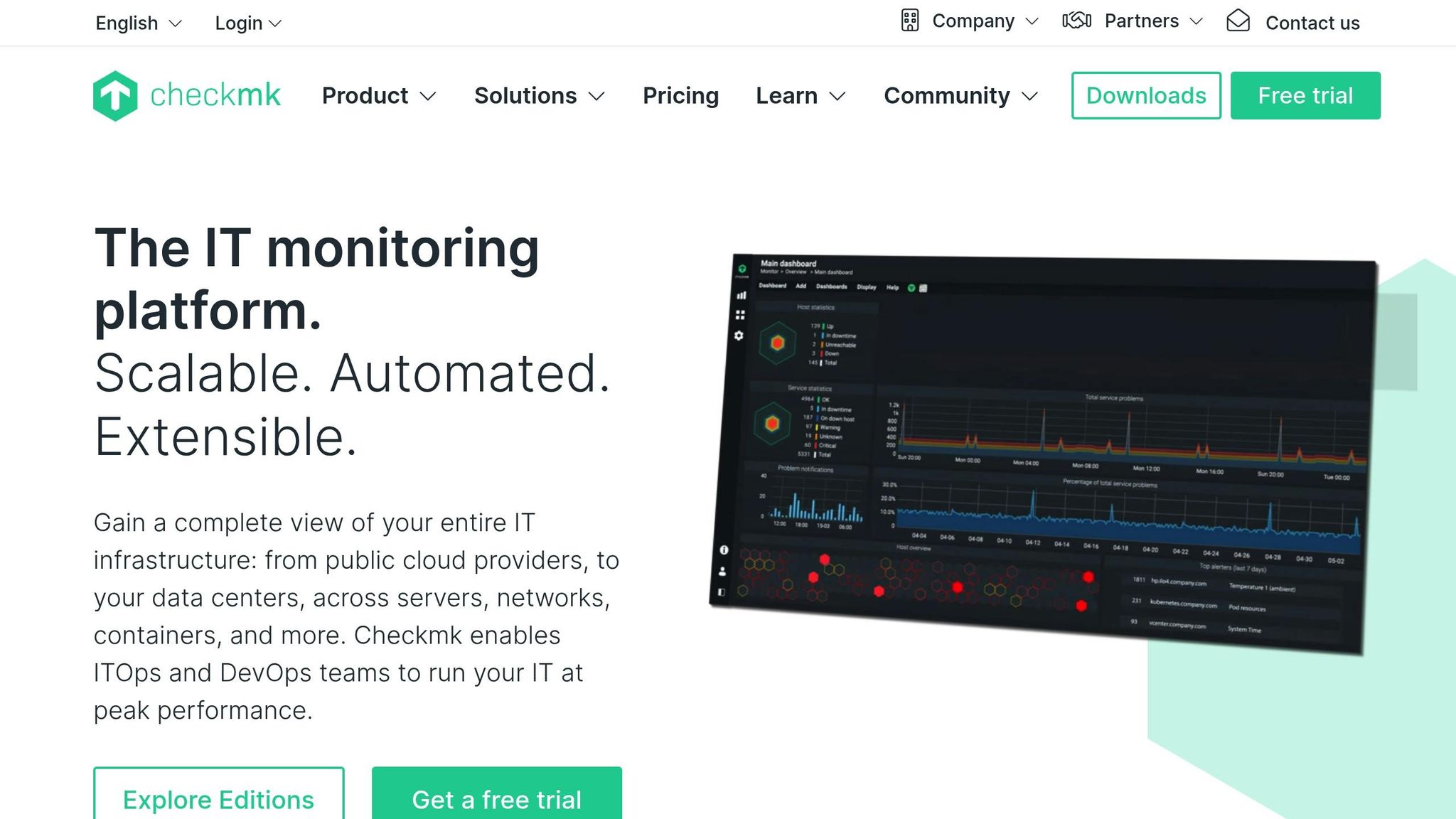
Checkmk proporciona paneles de control en tiempo real que se actualizan continuamente, mostrando los estados de los hosts, las comprobaciones de servicio y las métricas de rendimiento a medida que cambian. Admite el sondeo rápido de hosts críticos y puede mostrar gráficos en tiempo real de la carga, la memoria, la red y el estado de las aplicaciones. Los paneles son personalizables, por lo que los equipos pueden destacar los sistemas prioritarios y sacar a la luz rápidamente los problemas urgentes. Su eficiente núcleo de supervisión mantiene la sobrecarga baja incluso con miles de comprobaciones por minuto, lo que permite a las grandes configuraciones mantener una visibilidad en tiempo real con capacidad de respuesta.
Funciones de IA y automatización
Checkmk incluye el ajuste automatizado de umbrales y el procesamiento inteligente de reglas que reducen la fatiga de las alertas adaptándose al comportamiento de referencia. Puede descubrir hosts y servicios automáticamente y aplicar reglas de supervisión predefinidas sin necesidad de configuración manual. Las funciones predictivas soportan el análisis de tendencias y la planificación de capacidades, ayudando a los equipos a detectar a tiempo los riesgos de saturación. Para entornos complejos, su sistema de automatización basado en reglas agiliza las actualizaciones de configuración, la activación de comprobaciones y la lógica de notificación. Las funciones de IA más profundas suelen requerir el emparejamiento con herramientas de análisis externas, ya que Checkmk se centra en la supervisión determinista más que en la automatización completa de incidencias.
Facilidad de implantación
Checkmk es fácil de implantar, con un proceso de instalación rápido y guías de configuración claras. La edición raw utiliza componentes de código abierto, mientras que la edición enterprise incluye una interfaz de usuario perfeccionada y mejoras de rendimiento. Los agentes pueden instalarse con un pequeño script, y la detección automática detecta nuevos servicios inmediatamente. Se integra bien con entornos virtualizados y en contenedores, y se escala fácilmente a través de sitios de monitorización distribuidos para despliegues grandes o multiregionales. Dado que ofrece sólidos valores predeterminados, los equipos pueden poner en marcha rápidamente un sistema de supervisión completo sin necesidad de realizar grandes ajustes.
Precios
Checkmk ofrece una edición básica gratuita que incluye supervisión básica, paneles de control y alertas, por lo que es adecuada para equipos pequeños o entornos de laboratorio. La edición para empresas añade funciones avanzadas como mejor rendimiento, automatización ampliada, análisis predictivo e informes a largo plazo. El precio de la edición empresarial se basa normalmente en el número de hosts supervisados, empezando por un nivel básico accesible y escalando para infraestructuras más grandes. Esto mantiene los costes totales predecibles y resulta atractivo para las organizaciones que desean un sistema de supervisión potente sin elevadas tarifas de uso al estilo SaaS.