Zakres monitorowania
Checkmk obejmuje szeroki zakres monitorowania, śledząc infrastrukturę, sieci, aplikacje, kontenery i usługi w chmurze z poziomu jednej platformy. Oferuje dogłębne kontrole hostów i usług dzięki dużemu katalogowi wtyczek monitorujących, umożliwiając obserwację stanu sprzętu, baz danych, systemów pamięci masowej, warstw wirtualizacji i niestandardowych aplikacji. Zbiera szczegółowe metryki w krótkich odstępach czasu i koreluje zmiany stanu w różnych systemach, aby podkreślić pojawiające się problemy. Jego hybrydowa konstrukcja obsługuje zarówno monitorowanie oparte na agentach, jak i bez agentów, zapewniając elastyczność w centrach danych, konfiguracjach lokalnych i środowiskach rozproszonych.
Możliwości w czasie rzeczywistym
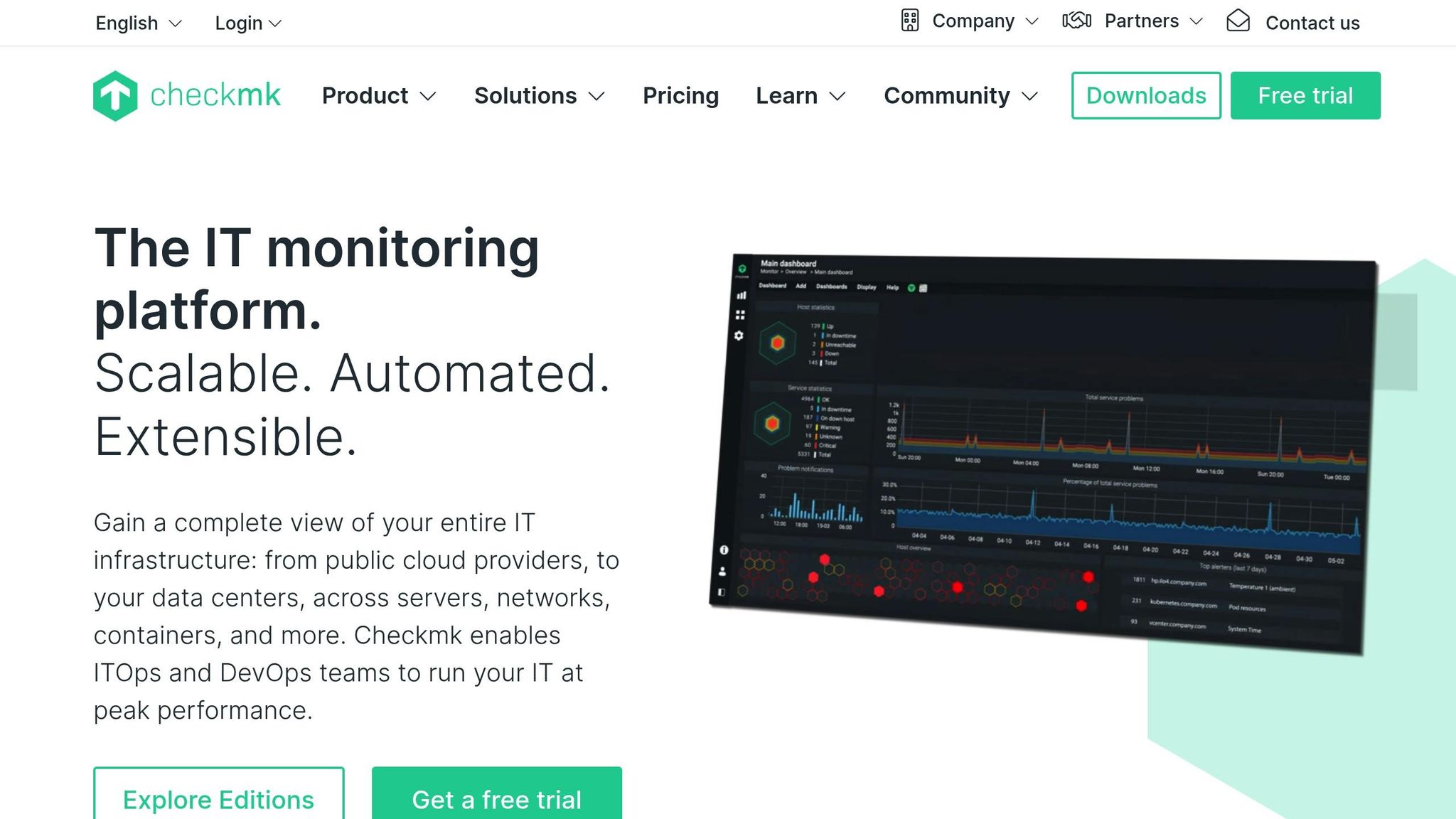
Checkmk zapewnia pulpity nawigacyjne na żywo, które aktualizują się w sposób ciągły, pokazując stany hostów, kontrole usług i wskaźniki wydajności w miarę ich zmian. Obsługuje szybkie odpytywanie krytycznych hostów i może wyświetlać wykresy obciążenia, pamięci, sieci i stanu aplikacji w czasie rzeczywistym. Pulpity są konfigurowalne, dzięki czemu zespoły mogą wyróżniać priorytetowe systemy i szybko wykrywać pilne problemy. Jego wydajny rdzeń monitorujący utrzymuje koszty ogólne na niskim poziomie nawet przy tysiącach sprawdzeń na minutę, umożliwiając dużym konfiguracjom utrzymanie responsywnej widoczności w czasie rzeczywistym.
Funkcje sztucznej inteligencji i automatyzacji
Checkmk obejmuje automatyczne dostrajanie progów i inteligentne przetwarzanie reguł, które zmniejszają zmęczenie alertami, dostosowując się do podstawowego zachowania. Może automatycznie wykrywać hosty i usługi oraz stosować predefiniowane reguły monitorowania bez ręcznej konfiguracji. Funkcje predykcyjne wspierają analizę trendów i planowanie wydajności, pomagając zespołom wcześnie wykryć ryzyko nasycenia. W przypadku złożonych środowisk system automatyzacji oparty na regułach usprawnia aktualizacje konfiguracji, aktywację kontroli i logikę powiadomień. Głębsze funkcje sztucznej inteligencji zwykle wymagają sparowania z zewnętrznymi narzędziami analitycznymi, ponieważ Checkmk koncentruje się na deterministycznym monitorowaniu, a nie na pełnej automatyzacji incydentów.
Łatwość wdrożenia
Checkmk jest łatwy do wdrożenia dzięki szybkiemu procesowi instalacji i przejrzystym przewodnikom konfiguracji. Surowa wersja wykorzystuje komponenty open source, podczas gdy wersja dla przedsiębiorstw zawiera udoskonalony interfejs użytkownika i ulepszenia wydajności. Agentów można zainstalować za pomocą niewielkiego skryptu, a automatyczne wykrywanie natychmiast wykrywa nowe usługi. Dobrze integruje się ze środowiskami zwirtualizowanymi i konteneryzowanymi, a także łatwo skaluje się za pomocą rozproszonych witryn monitorowania dla dużych lub wielo-regionalnych wdrożeń. Ponieważ oferuje silne ustawienia domyślne po wyjęciu z pudełka, zespoły mogą szybko uruchomić pełny system monitorowania bez konieczności intensywnego dostrajania.
Ceny
Checkmk oferuje bezpłatną wersję surową, która obejmuje podstawowe monitorowanie, pulpity nawigacyjne i alerty, dzięki czemu jest odpowiednia dla małych zespołów lub środowisk laboratoryjnych. Edycja dla przedsiębiorstw dodaje zaawansowane funkcje, takie jak lepsza wydajność, rozszerzona automatyzacja, analizy predykcyjne i długoterminowe raportowanie. Ceny edycji Enterprise są zazwyczaj oparte na liczbie monitorowanych hostów, zaczynając od przystępnego poziomu podstawowego i skalując dla większych infrastruktur. Dzięki temu ogólne koszty są przewidywalne i atrakcyjne dla organizacji, które chcą potężnego systemu monitorowania bez wysokich opłat za użytkowanie w stylu SaaS.