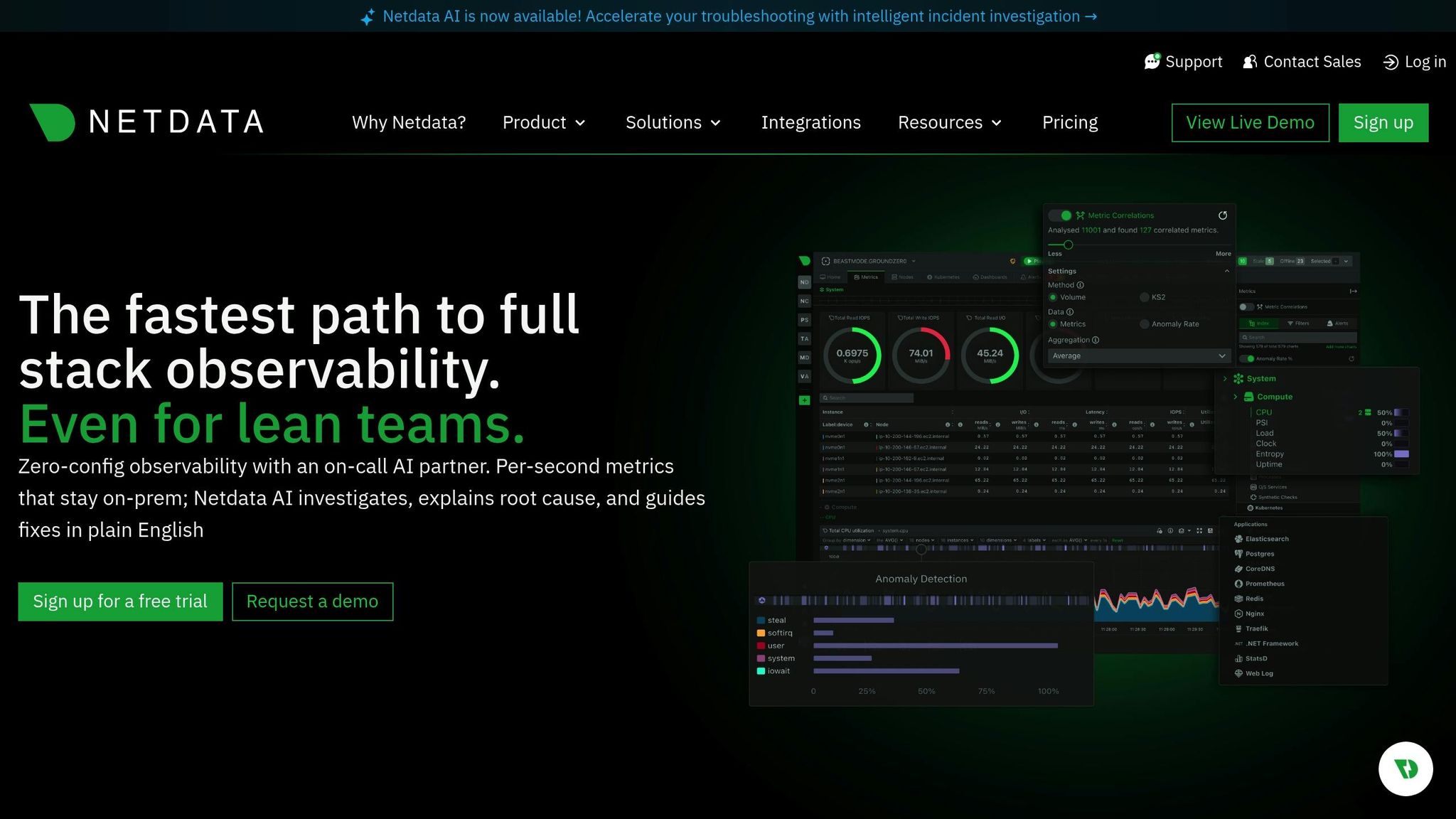
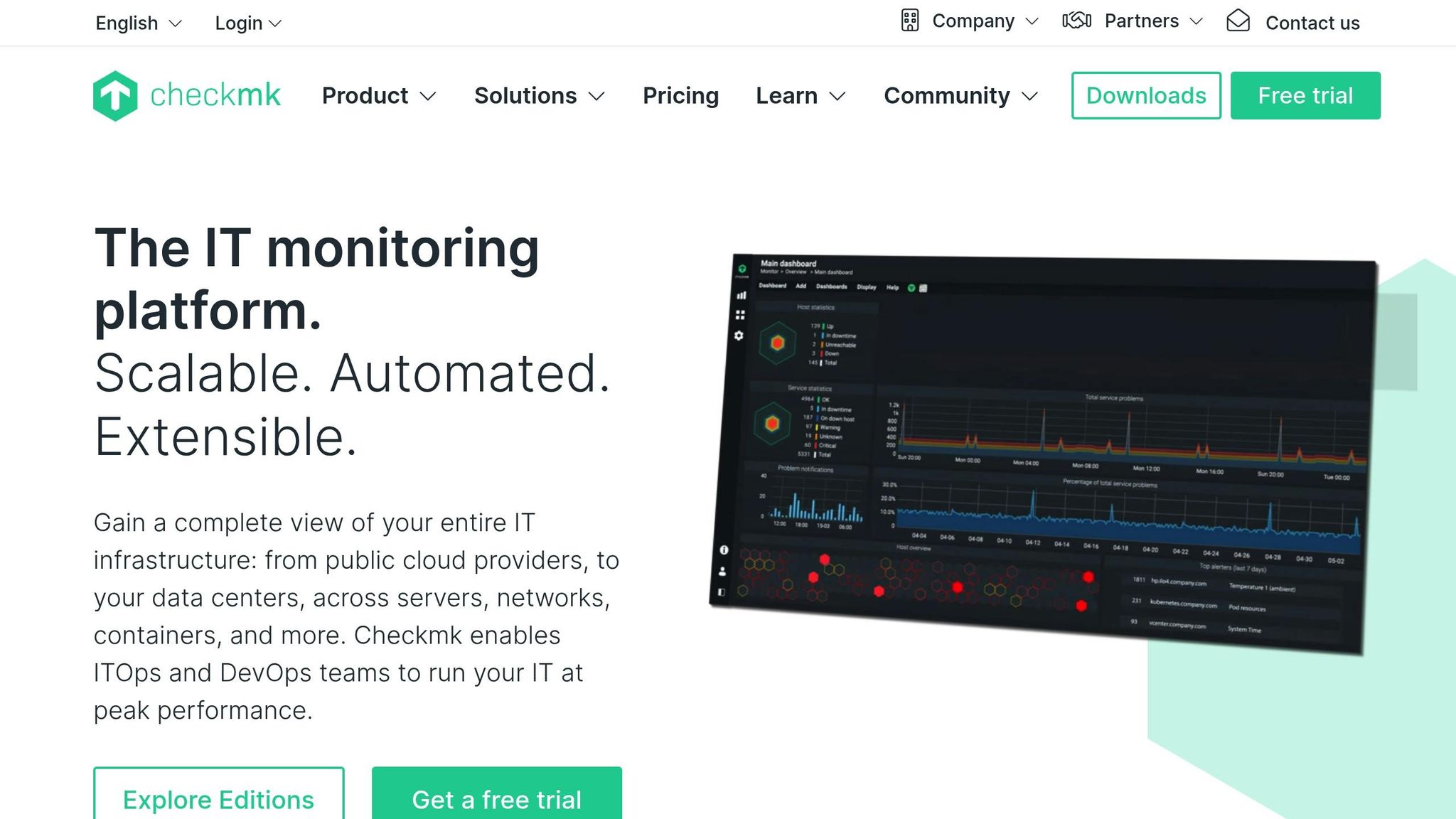
Ambito di monitoraggio
Checkmk copre un'ampia area di monitoraggio, monitorando infrastrutture, reti, applicazioni, container e servizi cloud da un'unica piattaforma. Offre controlli approfonditi su host e servizi grazie all'ampio catalogo di plugin di monitoraggio, consentendo di osservare lo stato di salute di hardware, database, sistemi di storage, livelli di virtualizzazione e applicazioni personalizzate. Raccoglie metriche dettagliate a brevi intervalli e correla le variazioni di stato tra i sistemi per evidenziare i problemi emergenti. Il suo design ibrido supporta sia il monitoraggio basato su agenti che quello senza agenti, offrendo flessibilità nei data center, nelle configurazioni on premises e negli ambienti distribuiti.
Funzionalità in tempo reale
Checkmk offre dashboard in tempo reale che si aggiornano continuamente, mostrando gli stati degli host, i controlli dei servizi e le metriche delle prestazioni man mano che cambiano. Supporta il polling rapido per gli host critici e può visualizzare grafici in tempo reale per il carico, la memoria, la rete e la salute delle applicazioni. I cruscotti sono personalizzabili, in modo che i team possano evidenziare i sistemi prioritari e far emergere rapidamente i problemi urgenti. Il suo efficiente nucleo di monitoraggio mantiene bassi i costi generali anche con migliaia di controlli al minuto, consentendo alle grandi configurazioni di mantenere una visibilità reattiva in tempo reale.
Funzionalità di intelligenza artificiale e automazione
Checkmk include la regolazione automatica delle soglie e l'elaborazione intelligente delle regole che riducono l'affaticamento degli avvisi adattandosi al comportamento di base. È in grado di rilevare automaticamente host e servizi e di applicare regole di monitoraggio predefinite senza necessità di configurazione manuale. Le funzioni predittive supportano l'analisi delle tendenze e la pianificazione della capacità, aiutando i team a individuare tempestivamente i rischi di saturazione. Per gli ambienti complessi, il sistema di automazione basato su regole semplifica gli aggiornamenti della configurazione, l'attivazione dei controlli e la logica di notifica. Le funzioni AI più profonde richiedono solitamente l'abbinamento con strumenti di analisi esterni, poiché Checkmk si concentra sul monitoraggio deterministico piuttosto che sull'automazione completa degli incidenti.
Facilità di implementazione
Checkmk è semplice da implementare, con un processo di installazione rapido e guide di configurazione chiare. L'edizione raw utilizza componenti open source, mentre l'edizione enterprise include un'interfaccia utente perfezionata e miglioramenti delle prestazioni. Gli agenti possono essere installati con un piccolo script e il rilevamento automatico rileva immediatamente i nuovi servizi. Si integra bene con gli ambienti virtualizzati e containerizzati e si scala facilmente attraverso siti di monitoraggio distribuiti per implementazioni di grandi dimensioni o in più regioni. Poiché offre forti impostazioni predefinite, i team possono ottenere rapidamente un sistema di monitoraggio completo senza dover effettuare una messa a punto approfondita.
Prezzi
Checkmk offre un'edizione grezza gratuita che include il monitoraggio di base, i dashboard e gli avvisi, rendendola adatta a piccoli team o ambienti di laboratorio. L'edizione enterprise aggiunge funzionalità avanzate come migliori prestazioni, automazione estesa, analisi predittiva e reportistica a lungo termine. I prezzi dell'edizione enterprise si basano in genere sul numero di host monitorati, partendo da un livello iniziale accessibile e scalando per le infrastrutture più grandi. In questo modo i costi complessivi rimangono prevedibili e sono interessanti per le organizzazioni che desiderano un sistema di monitoraggio potente senza elevati costi di utilizzo in stile SaaS.