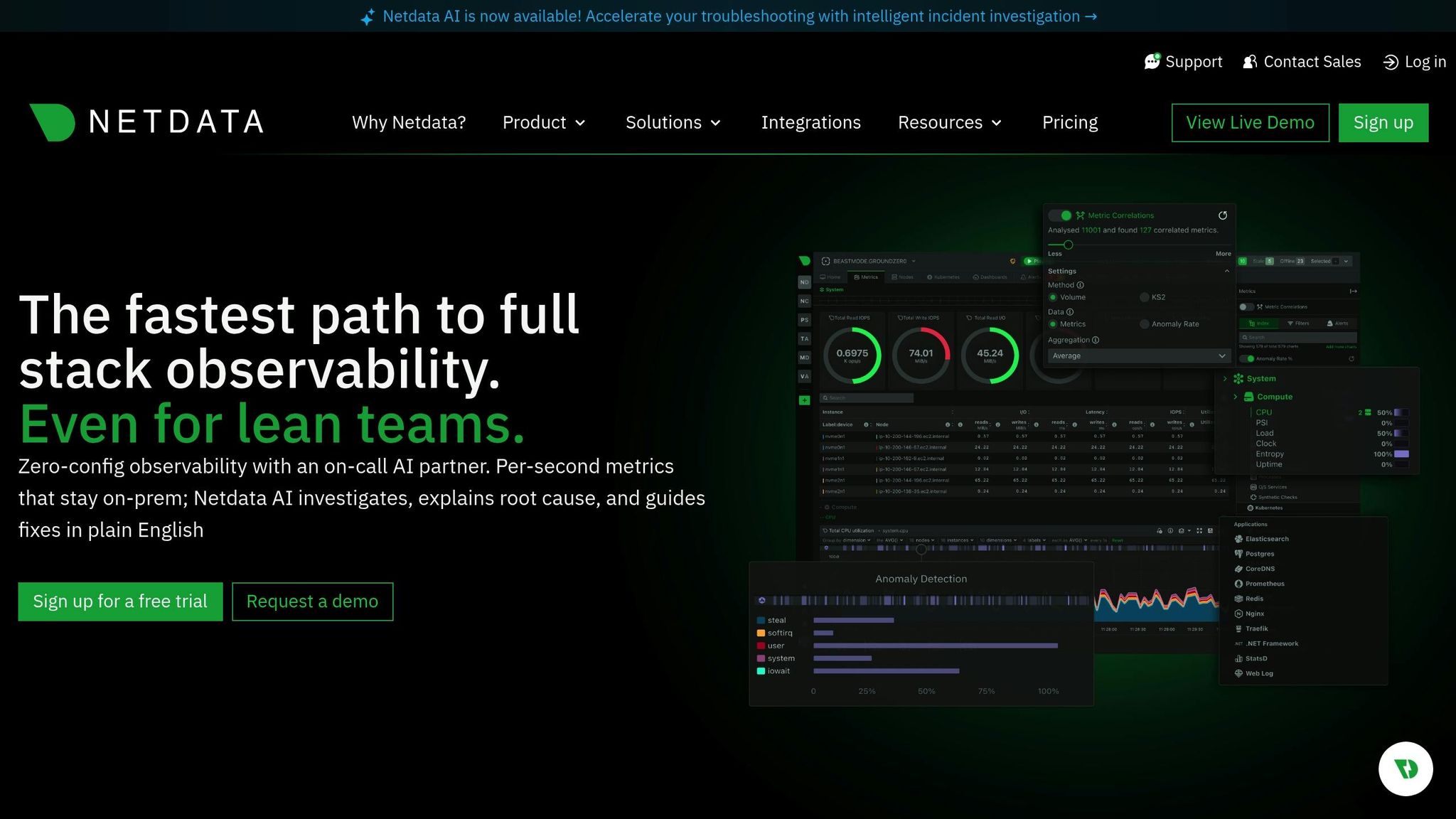
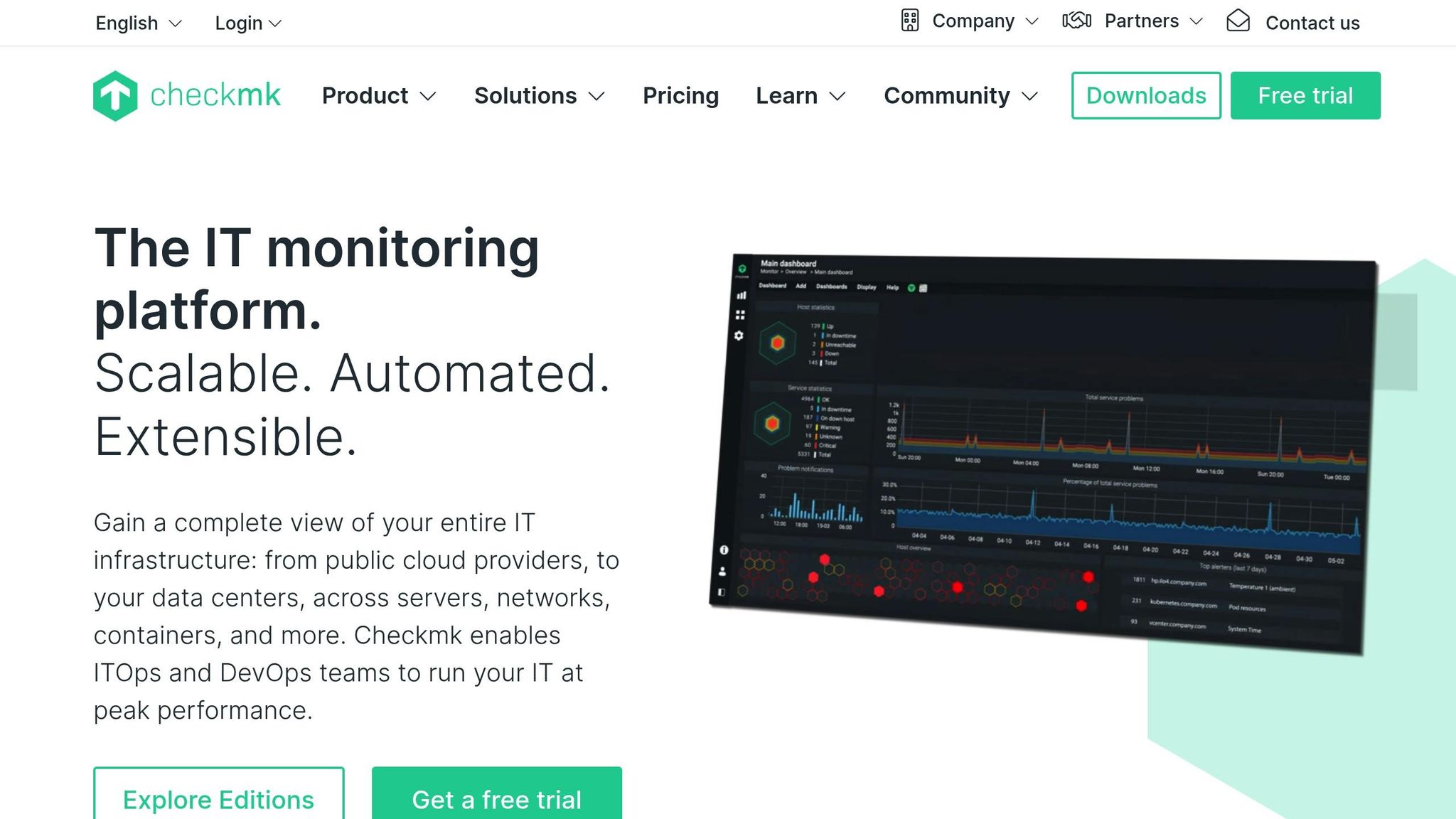
Сфера моніторингу
Checkmk охоплює широку сферу моніторингу, відстежуючи інфраструктуру, мережі, програми, контейнери та хмарні сервіси з однієї платформи. Він пропонує глибоку перевірку хостів і сервісів за допомогою великого каталогу плагінів для моніторингу, що дозволяє спостерігати за станом обладнання, баз даних, систем зберігання, рівнів віртуалізації та користувацьких додатків. Він збирає детальні показники через короткі проміжки часу і співвідносить зміни стану в різних системах, щоб виявити нові проблеми. Його гібридна конструкція підтримує моніторинг як на основі агентів, так і без них, забезпечуючи гнучкість у центрах обробки даних, локальних установках і розподілених середовищах.
Можливості в режимі реального часу
Checkmk надає інформаційні панелі в реальному часі, які постійно оновлюються, показуючи стани хостів, перевірки сервісів і показники продуктивності в міру їх зміни. Він підтримує швидке опитування критично важливих хостів і може відображати графіки навантаження, пам'яті, мережі та працездатності додатків у реальному часі. Панелі моніторингу налаштовуються, тому команди можуть виділяти пріоритетні системи та швидко виявляти нагальні проблеми. Ефективне ядро моніторингу забезпечує низький рівень накладних витрат навіть при тисячах перевірок на хвилину, що дозволяє великим організаціям підтримувати оперативну видимість у реальному часі.
Функції штучного інтелекту та автоматизації
Checkmk включає автоматичне налаштування порогових значень і інтелектуальну обробку правил, які зменшують втому від сповіщень, адаптуючись до базової поведінки. Він може автоматично виявляти хости і сервіси та застосовувати попередньо визначені правила моніторингу без ручного налаштування. Функції прогнозування підтримують аналіз тенденцій і планування потужностей, допомагаючи командам на ранніх стадіях виявляти ризики перенасичення. У складних середовищах система автоматизації на основі правил оптимізує оновлення конфігурації, перевірку активації та логіку сповіщень. Більш глибокі функції ШІ зазвичай вимагають поєднання із зовнішніми інструментами аналітики, оскільки Checkmk фокусується на детермінованому моніторингу, а не на повній автоматизації інцидентів.
Простота розгортання
Checkmk простий у розгортанні завдяки швидкому процесу встановлення та зрозумілим інструкціям з налаштування. Сира версія використовує компоненти з відкритим вихідним кодом, в той час як корпоративна версія включає вдосконалений інтерфейс і покращену продуктивність. Агенти можуть бути встановлені за допомогою невеликого скрипта, а автоматичне виявлення миттєво виявляє нові сервіси. Він добре інтегрується з віртуалізованими та контейнерними середовищами і легко масштабується за допомогою розподілених сайтів моніторингу для великих або регіональних розгортань. Завдяки потужним налаштуванням за замовчуванням з коробки, команди можуть швидко запустити повноцінну систему моніторингу без значних налаштувань.
Ціноутворення
Checkmk надає безкоштовну сиру версію, яка включає основний моніторинг, інформаційні панелі та сповіщення, що робить її придатною для невеликих команд або лабораторних середовищ. Корпоративна версія додає розширені функції, такі як краща продуктивність, розширена автоматизація, предиктивна аналітика і довгострокові звіти. Ціна на корпоративну версію зазвичай базується на кількості хостів, за якими здійснюється моніторинг, починаючи з доступного початкового рівня і масштабування для більших інфраструктур. Це робить загальні витрати передбачуваними і привабливими для організацій, які хочуть отримати потужну систему моніторингу без високої плати за використання в стилі SaaS.