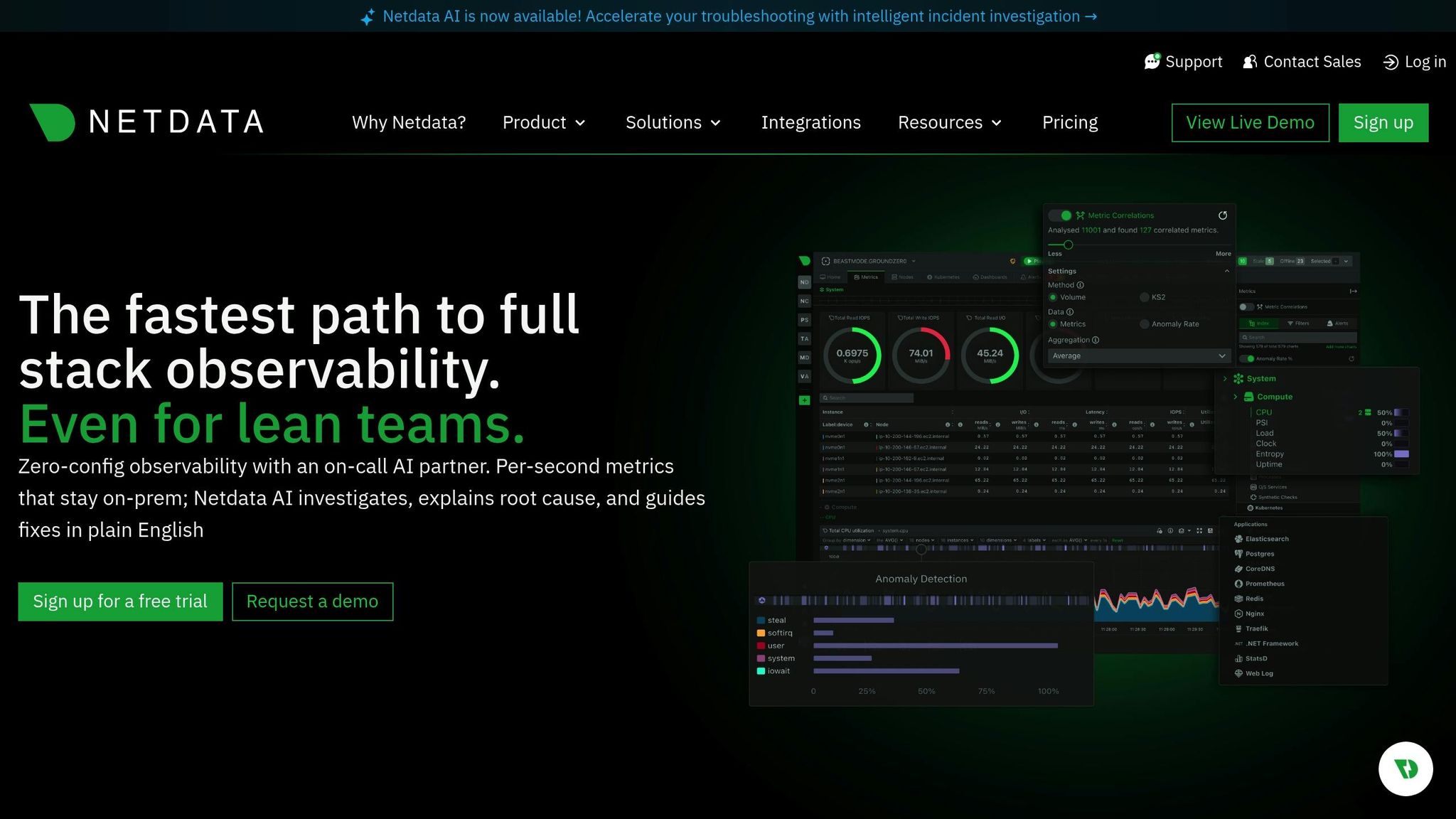
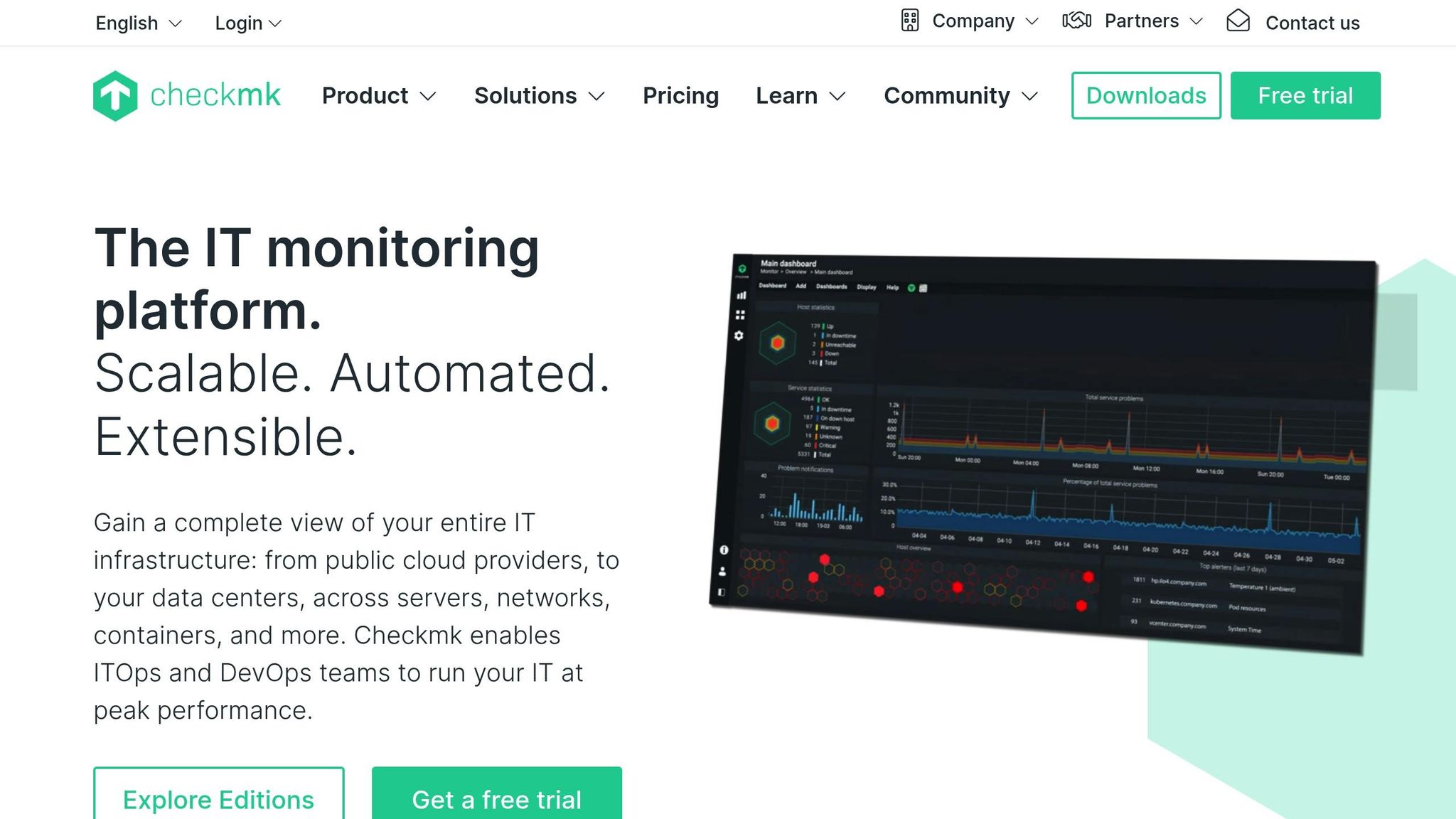
Область мониторинга
Checkmk охватывает широкую область мониторинга, отслеживая инфраструктуру, сети, приложения, контейнеры и облачные сервисы с помощью единой платформы. Он предлагает глубокую проверку хостов и сервисов с помощью обширного каталога плагинов для мониторинга, позволяя наблюдать за состоянием оборудования, баз данных, систем хранения, уровней виртуализации и пользовательских приложений. Он собирает подробные метрики через короткие промежутки времени и сопоставляет изменения состояния различных систем, чтобы выявить возникающие проблемы. Гибридная конструкция поддерживает как агентский, так и безагентский мониторинг, что обеспечивает гибкость в центрах обработки данных, локальных и распределенных средах.
Возможности в режиме реального времени
Checkmk предоставляет постоянно обновляемые панели, на которых отображаются состояния хостов, проверки служб и показатели производительности по мере их изменения. Он поддерживает быстрый опрос критически важных узлов и может отображать графики нагрузки, памяти, состояния сети и приложений в реальном времени. Приборные панели настраиваются, поэтому команды могут выделять приоритетные системы и быстро выявлять срочные проблемы. Эффективное ядро мониторинга позволяет снизить накладные расходы даже при тысячах проверок в минуту, что позволяет крупным системам поддерживать оперативное наблюдение в режиме реального времени.
Функции искусственного интеллекта и автоматизации
Checkmk включает автоматическую настройку порогов и интеллектуальную обработку правил, которые снижают усталость от оповещений, адаптируясь к базовому поведению. Он может автоматически обнаруживать хосты и службы и применять предопределенные правила мониторинга без ручной настройки. Функции прогнозирования поддерживают анализ тенденций и планирование мощностей, помогая командам выявлять риски перенасыщения на ранней стадии. Для сложных сред система автоматизации на основе правил упрощает обновление конфигурации, активацию проверок и логику уведомлений. Более глубокие функции искусственного интеллекта обычно требуют сопряжения с внешними аналитическими инструментами, поскольку Checkmk фокусируется на детерминированном мониторинге, а не на полной автоматизации инцидентов.
Простота развертывания
Checkmk прост в развертывании благодаря быстрому процессу установки и понятным руководствам по настройке. Необработанная версия использует компоненты с открытым исходным кодом, а корпоративная версия включает в себя усовершенствованный пользовательский интерфейс и улучшения производительности. Агенты можно установить с помощью небольшого сценария, а автоматическое обнаружение сразу же обнаруживает новые службы. Он хорошо интегрируется с виртуализированными и контейнерными средами и легко масштабируется с помощью распределенных сайтов мониторинга для крупных или многорегиональных развертываний. Благодаря тому, что он предлагает сильные настройки по умолчанию из коробки, команды могут быстро запустить полноценную систему мониторинга без длительной настройки.
Ценообразование
Checkmk предоставляет бесплатную сырую версию, которая включает в себя основной мониторинг, панели мониторинга и оповещения, что делает ее подходящей для небольших команд или лабораторных сред. Корпоративная версия добавляет расширенные функции, такие как повышение производительности, расширенная автоматизация, предиктивная аналитика и долгосрочная отчетность. Цены на корпоративную версию обычно зависят от количества контролируемых хостов, начиная с доступного начального уровня и масштабируясь для более крупных инфраструктур. Это делает общую стоимость предсказуемой и привлекательной для организаций, которым нужна мощная система мониторинга без высокой платы за использование в стиле SaaS.