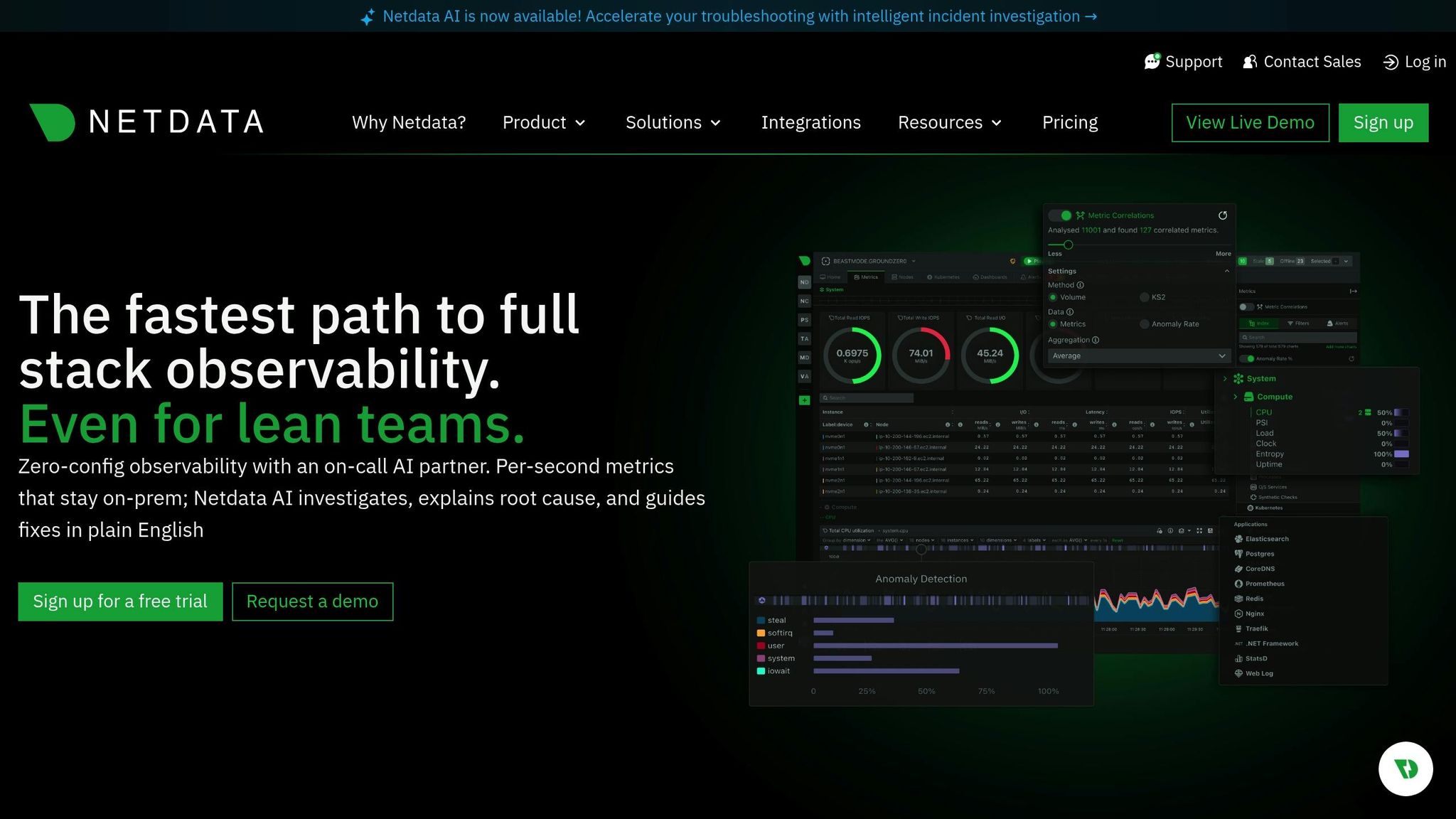
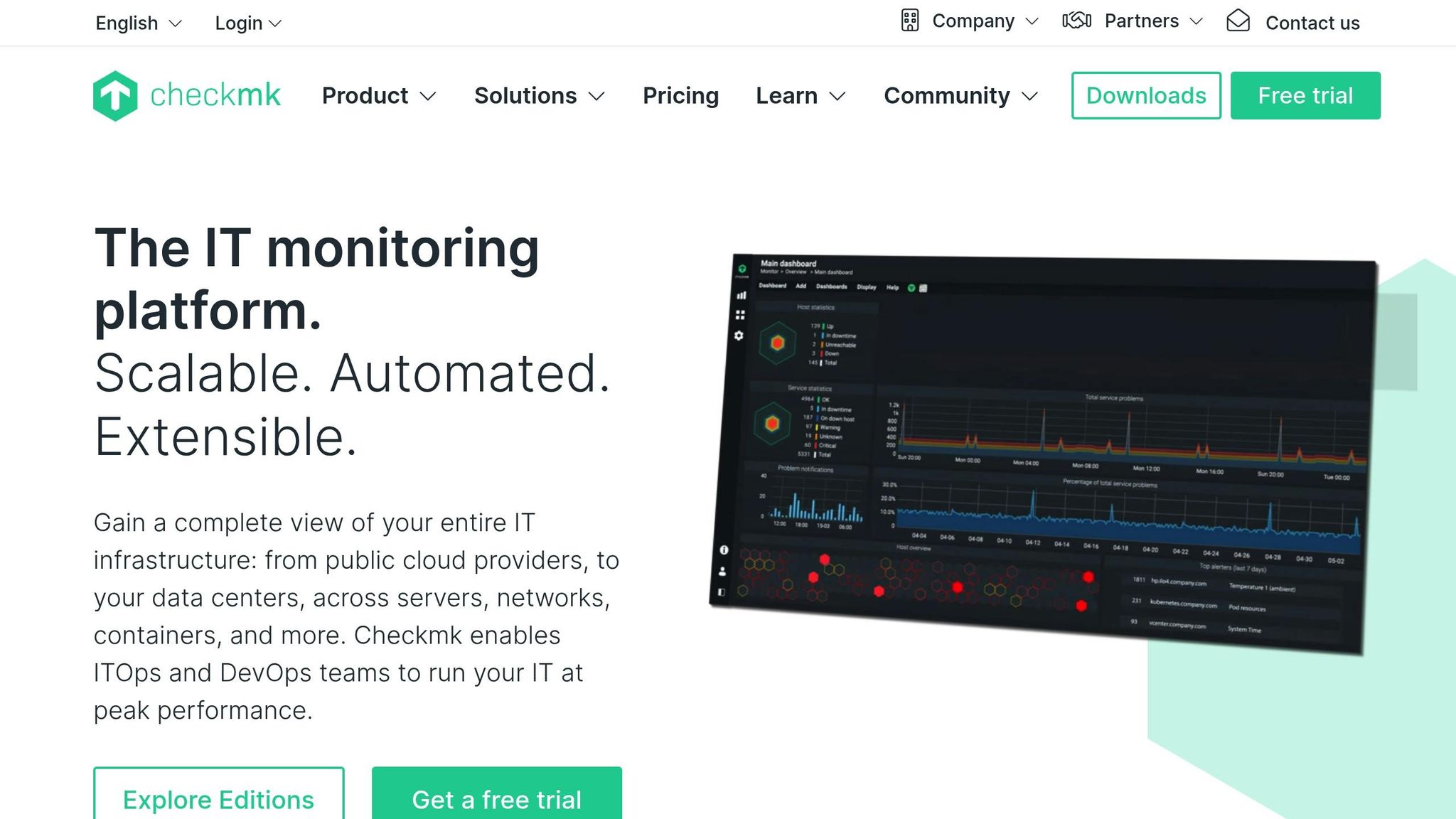
Domeniul de monitorizare
Checkmk acoperă o amprentă largă de monitorizare, urmărind infrastructura, rețelele, aplicațiile, containerele și serviciile cloud de pe o singură platformă. Acesta oferă verificări aprofundate ale gazdelor și serviciilor prin intermediul catalogului său mare de pluginuri de monitorizare, permițându-vă să observați starea hardware, bazele de date, sistemele de stocare, straturile de virtualizare și aplicațiile personalizate. Acesta colectează metrici detaliate la intervale scurte și corelează modificările de stare ale sistemelor pentru a evidenția problemele emergente. Designul său hibrid suportă atât monitorizarea bazată pe agenți, cât și monitorizarea fără agenți, oferind flexibilitate în centrele de date, în configurațiile locale și în mediile distribuite.
Capabilități în timp real
Checkmk oferă tablouri de bord live care se actualizează continuu, afișând stările gazdelor, verificările serviciilor și parametrii de performanță pe măsură ce aceștia se modifică. Suportă sondarea rapidă a gazdelor critice și poate afișa grafice în timp real pentru încărcare, memorie, rețea și starea aplicațiilor. Tablourile de bord sunt personalizabile, astfel încât echipele pot evidenția sistemele prioritare și pot scoate rapid la suprafață problemele urgente. Nucleul său eficient de monitorizare menține un nivel scăzut al cheltuielilor generale, chiar și cu mii de verificări pe minut, permițând configurațiilor mari să mențină vizibilitatea în timp real.
Caracteristici de inteligență artificială și automatizare
Checkmk include reglarea automată a pragurilor și procesarea inteligentă a regulilor care reduc oboseala alertelor prin adaptarea la comportamentul de bază. Acesta poate descoperi automat gazde și servicii și poate aplica reguli de monitorizare predefinite fără configurare manuală. Funcțiile predictive sprijină analiza tendințelor și planificarea capacității, ajutând echipele să identifice din timp riscurile de saturație. Pentru mediile complexe, sistemul său de automatizare bazat pe reguli simplifică actualizările configurației, activarea verificărilor și logica de notificare. Funcțiile AI mai profunde necesită, de obicei, asocierea cu instrumente analitice externe, deoarece Checkmk se concentrează pe monitorizarea deterministă mai degrabă decât pe automatizarea completă a incidentelor.
Ușurința implementării
Checkmk este simplu de implementat, cu un proces rapid de instalare și ghiduri clare de configurare. Ediția brută utilizează componente open source, în timp ce ediția enterprise include o interfață rafinată și îmbunătățiri ale performanței. Agenții pot fi instalați cu un mic script, iar descoperirea automată detectează imediat noile servicii. Se integrează bine cu mediile virtualizate și containerizate și se scalează ușor prin site-uri de monitorizare distribuite pentru implementări mari sau în mai multe regiuni. Deoarece oferă valori implicite puternice din fabrică, echipele pot pune rapid în funcțiune un sistem de monitorizare complet, fără ajustări ample.
Prețuri
Checkmk oferă o ediție brută gratuită care include monitorizarea de bază, tablouri de bord și alerte, ceea ce o face potrivită pentru echipe mici sau medii de laborator. Ediția enterprise adaugă caracteristici avansate, cum ar fi performanță mai bună, automatizare extinsă, analiză predictivă și raportare pe termen lung. Prețurile pentru ediția enterprise se bazează de obicei pe numărul de gazde monitorizate, începând de la un nivel de bază accesibil și crescând pentru infrastructuri mai mari. Astfel, costurile totale rămân previzibile și atractive pentru organizațiile care doresc un sistem de monitorizare puternic, fără taxe de utilizare ridicate de tip SaaS.