Unmetered + Powerful
GPU Servers
High-performance GPUs, flexible configurations, and unmetered bandwidth to power AI, rendering, HPC, and streaming workloads at scale.
Choose now
AI Servers
GPU servers built for AI, rendering, HPC, and streaming - with unmetered bandwidth at global scale
Edge AI
- AMD EPYC CPU
- NVIDIA L4/L40s/H100
- 10/100 Gbps Unmetered
From:
$1,500/monthSet-up:
$1,000- 1U server
- AMD EPYC 9124/9354
- 192/384/768 GB RAM
- 3.84/7.68/15.34 TB NVMe
- Locations: US/EU/APAC
- Root access
- /29 IPv4 IP addresses (4 usable)
- /64 IPv6 on request
Core AI
- AMD EPYC CPU
- 2/4/8 x NVIDIA L4/L40s/H100
- 10/100 Gbps Unmetered
From:
$4,200/monthSet-up:
$2,800- 4U server
- AMD EPYC 9124/9354/9454/9654 CPU
- 384/768 GB DDR5 4800MHz RAM
- 3.84/7.68/15.34 TB NVMe Gen5
- Locations: US/EU/APAC
- Root access
- /29 IPv4 IP addresses (4 usable)
- /64 IPv6 on request
Max AI
- 2 x AMD EPYC CPUs
- 4/8 x L40s/H200/RTX PRO 6000
- 10/100 Gbps Unmetered
From:
$7,620/monthSet-up:
$5,080- 8U server
- 2 x AMD EPYC 9135/9355/9455/9555 CPU
- 384/768/1536 GB DDR5 4800MHz RAM
- 2 x 960GB SSD
- 3.84/7.68/15.34 TB NVMe Gen5
- Locations: US/EU/APAC
- Root access
- /29 IPv4 IP addresses (4 usable)
- /64 IPv6 on request
NVIDIA GH200 Special
The QuantaGrid S74G-2U with NVIDIA GH200 Grace Hopper delivers consistent, scalable performance, optimized for large-scale AI inference and HPC.
- QuantaGrid S74G-2U
- GH200 Grace Hopper SuperChip 96GB
- 72C Little Endian ArmV9
- 480GB RAM
- 10/100 Gbps Unmetered
- 1.92TB NVME SSD (E1.S)
- 960GB NVME SSD (M.2)
- $5,625 /month
Need a different set-up?
Features
Why Choose FDC For Your GPU
01
Scalable Clusters
Link multiple servers into a single high-performance environment with PVLAN Layer 2 networking. Ideal for multi-GPU training, distributed inference, or HPC workloads.

02
Unmatched Throughput
Harness the full power of dedicated GPUs paired with unmetered connections up to 400Gbps. AI inference, training, and rendering jobs run without bandwidth bottlenecks, delivering faster results at any scale.

03
Global Reach
Deploy in 27+ locations worldwide and link servers seamlessly with PVLAN Layer 2 connectivity. Build low-latency clusters across continents for AI, HPC, and media workloads.
04
Transparent Pricing
Our model is straightforward and predictable, no hidden fees, no surprise bills. You get enterprise-grade GPU servers with clear monthly rates you can rely on.

05
Enterprise-Grade Hardware
From NVIDIA H100 and H200 NVL to the GH200 Grace Hopper, our fleet is built on the latest compute and graphics platforms — ready for AI, HPC, and rendering at scale.

06
'Always on' Support
Our teams are available 24/7, 365 days a year to keep your projects running. From cluster builds to troubleshooting, you’ll always have experts on hand.

GPUs by workload usage
High-End Compute
Best for large-scale AI training, inference, and HPC (high performance computing) where budget is secondary to performance.
Top-tier for massive models and compute-heavy HPC.

Flagship for training, inference, and advanced research.

Hybrid CPU–GPU with coherent memory, ideal for HPC + inference at extreme scale.
Versatile & Efficient
Best for organizations balancing performance and cost, covering AI, rendering, and virtualized workloads.
Balanced compute + graphics, strong for training, rendering, and VDI.

Efficient production GPU for training and inference.

Small form factor, energy-efficient, optimized for inference and virtual environments.

Ready to order?
Choose your AI serverPerformance statistics
GPU line-up
Detailed Specifications
Our fleet spans the latest NVIDIA GPUs, from inference-optimized cards to multi-GPU compute platforms. The table below details key performance metrics, memory capacity, and workload suitability so you can match the right hardware to your AI, rendering, or HPC needs.
* denotes theoretical performance using sparsity
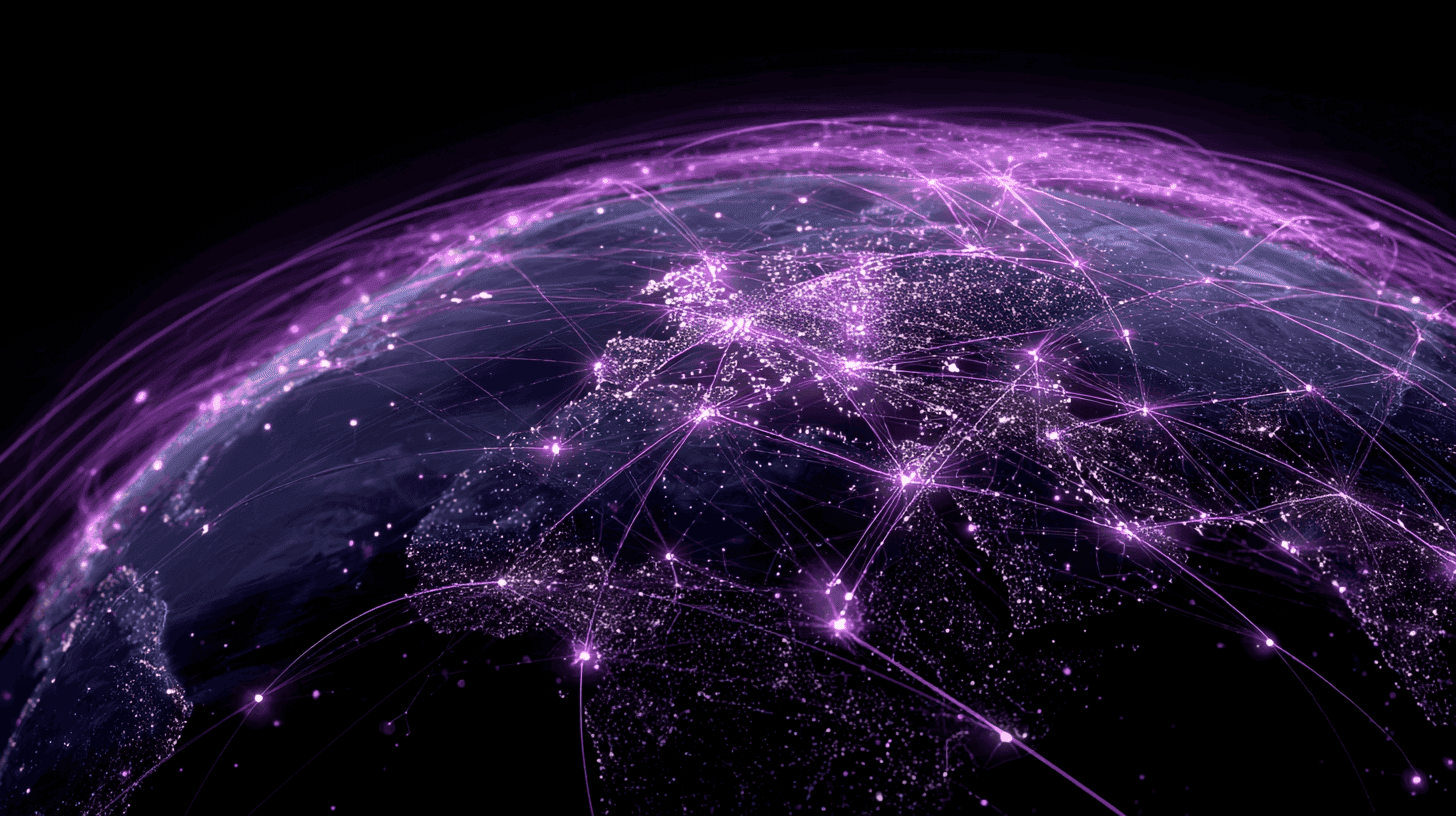
GPU deployment locations
Connecting the world
faq
Frequently asked questions
Our GPU Servers come with month to month contracts as standard, however our sales team are happy to discuss discounts based on longer terms or multiple GPU Servers
FDC GPU Servers can be customized via the order process with many options - however, should you require something more custom our sales team will be happy to give you a quote for any requirement.
As FDC GPU Servers are built on demand and can be customized to your needs there is a lead time for deployment - currently this is up to 1 week for North America, up to 2 weeks for Europe and can be up to 2-3 weeks for APAC and LATAM. However, this may also be considerably quicker depending on configuration - please talk to our sales team who will be happy to give you a lead time based on your requirements.
