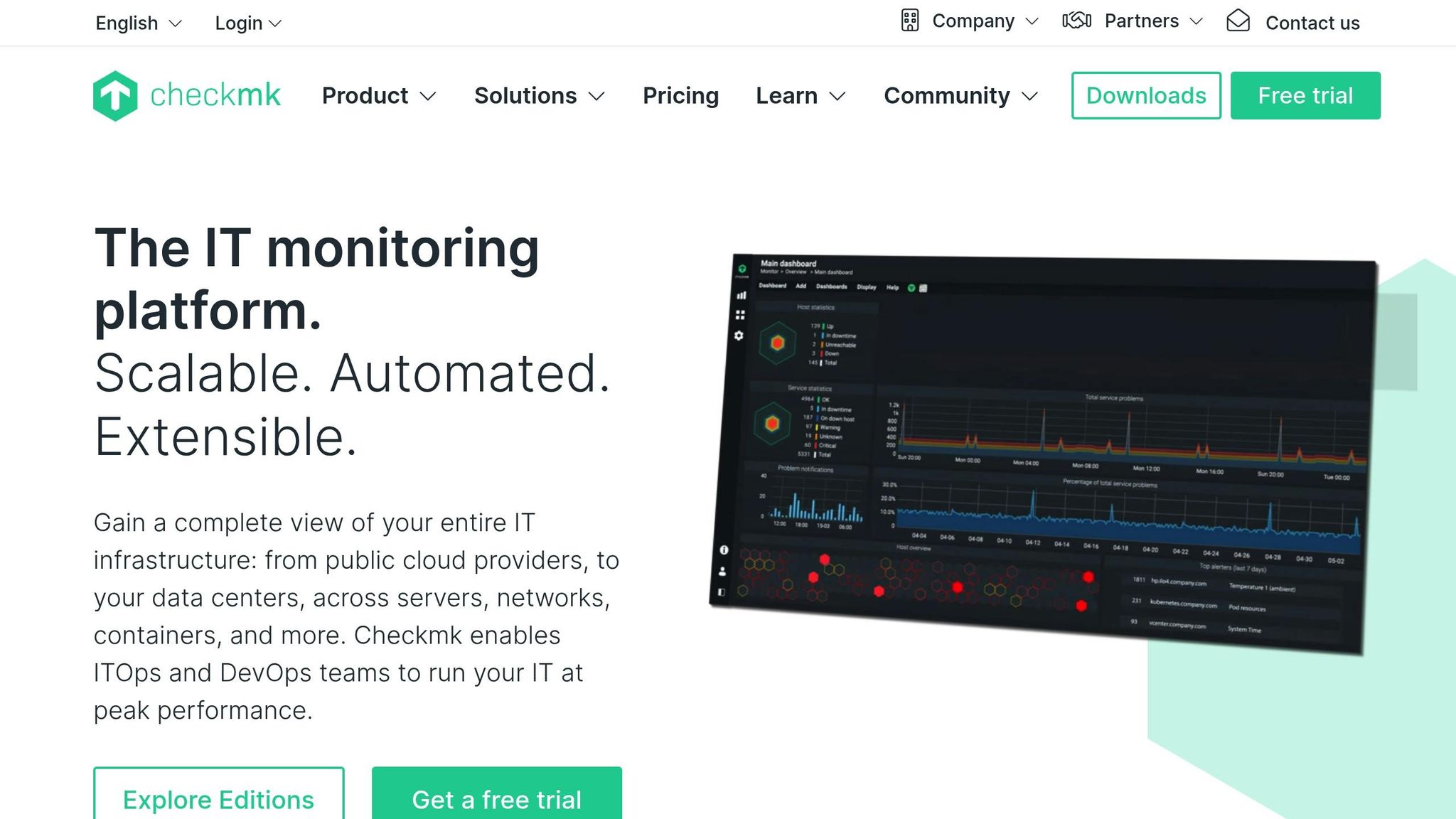
Rozsah monitorování
Checkmk pokrývá široký záběr monitorování, sleduje infrastrukturu, sítě, aplikace, kontejnery a cloudové služby z jediné platformy. Nabízí hloubkovou kontrolu hostitelů a služeb prostřednictvím rozsáhlého katalogu monitorovacích zásuvných modulů, které umožňují sledovat stav hardwaru, databází, úložných systémů, virtualizačních vrstev a vlastních aplikací. V krátkých intervalech shromažďuje podrobné metriky a koreluje změny stavu napříč systémy, aby upozornil na vznikající problémy. Jeho hybridní design podporuje monitorování založené na agentech i bez agentů, což poskytuje flexibilitu v datových centrech, lokálních nastaveních i distribuovaných prostředích.
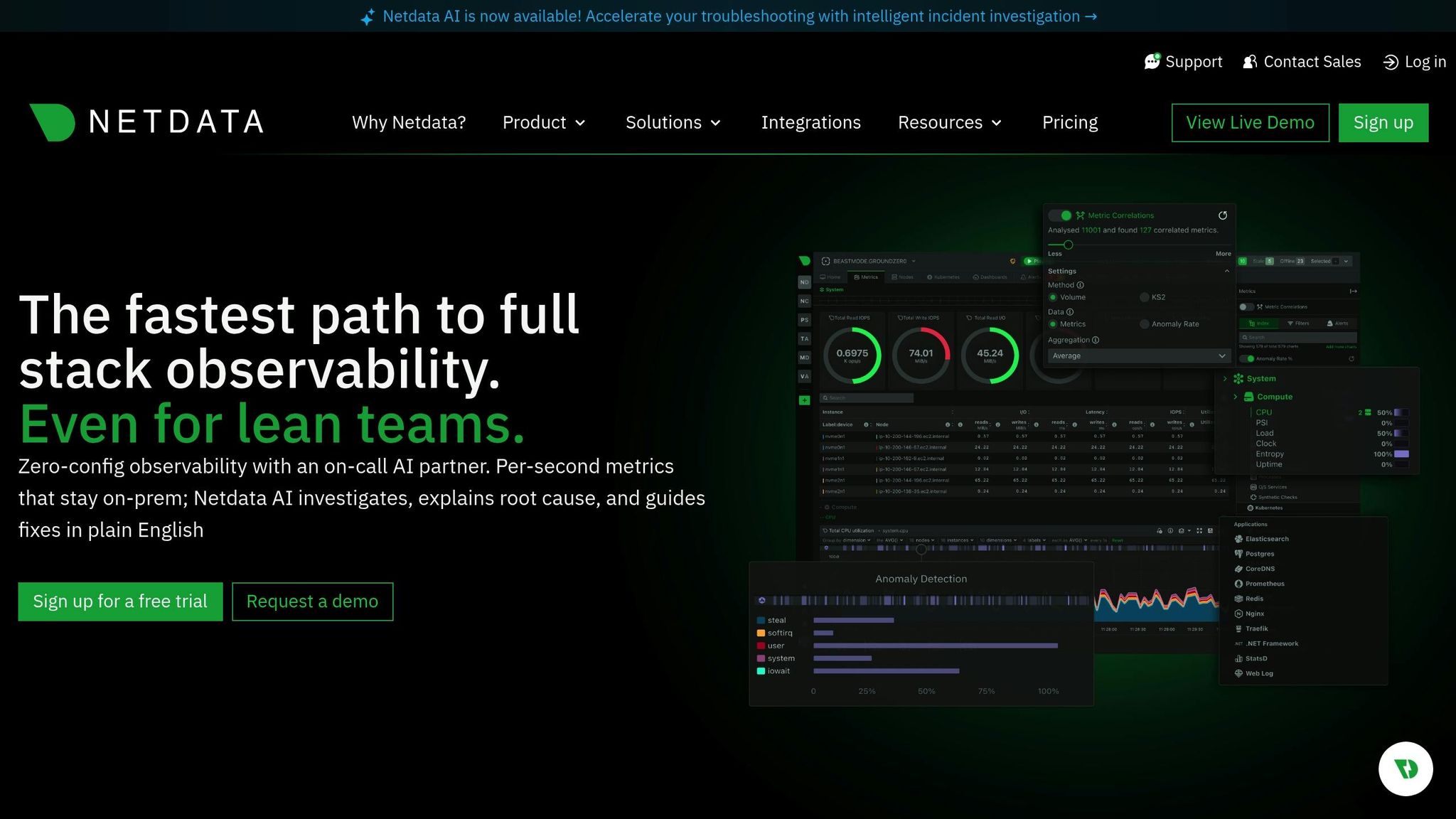
Schopnosti v reálném čase
Checkmk poskytuje živé řídicí panely, které se průběžně aktualizují a zobrazují stavy hostitelů, kontroly služeb a výkonnostní metriky podle jejich změn. Podporuje rychlé dotazování kritických hostitelů a dokáže zobrazovat grafy zatížení, paměti, sítě a stavu aplikací v reálném čase. Dashboardy jsou přizpůsobitelné, takže týmy mohou zvýraznit prioritní systémy a rychle odhalit naléhavé problémy. Jeho efektivní monitorovací jádro udržuje nízkou režii i při tisících kontrol za minutu, což umožňuje rozsáhlým sestavám zachovat citlivý přehled v reálném čase.
Funkce umělé inteligence a automatizace
Checkmk obsahuje automatické ladění prahů a inteligentní zpracování pravidel, které snižují únavu z upozornění tím, že se přizpůsobují základnímu chování. Dokáže automaticky zjišťovat hostitele a služby a aplikovat předdefinovaná monitorovací pravidla bez nutnosti ruční konfigurace. Prediktivní funkce podporují analýzu trendů a plánování kapacity a pomáhají týmům včas odhalit rizika nasycení. Pro složitá prostředí jeho systém automatizace založený na pravidlech zjednodušuje aktualizace konfigurace, aktivaci kontrol a logiku upozornění. Hlubší funkce AI obvykle vyžadují spárování s externími analytickými nástroji, protože Checkmk se zaměřuje spíše na deterministické monitorování než na plnou automatizaci incidentů.
Snadnost nasazení
Checkmk se snadno nasazuje díky rychlému procesu instalace a přehledným průvodcům nastavením. Edice raw využívá komponenty s otevřeným zdrojovým kódem, zatímco edice enterprise obsahuje vylepšené uživatelské rozhraní a vylepšení výkonu. Agenty lze nainstalovat pomocí malého skriptu a automatické zjišťování okamžitě detekuje nové služby. Dobře se integruje s virtualizovanými a kontejnerovými prostředími a snadno se škáluje prostřednictvím distribuovaných monitorovacích míst pro rozsáhlá nasazení nebo nasazení ve více regionech. Protože nabízí silné výchozí nastavení hned po vybalení, mohou týmy rychle zprovoznit plnohodnotný monitorovací systém bez rozsáhlého ladění.
Ceny
Checkmk poskytuje bezplatnou základní edici, která zahrnuje základní monitorování, ovládací panely a upozornění, takže je vhodná pro malé týmy nebo laboratorní prostředí. Podniková edice přidává pokročilé funkce, jako je vyšší výkon, rozšířená automatizace, prediktivní analýza a dlouhodobé reportování. Ceny podnikové edice se obvykle odvíjejí od počtu monitorovaných hostitelů, přičemž začínají na dostupné základní úrovni a škálují se pro větší infrastruktury. Díky tomu jsou celkové náklady předvídatelné a atraktivní pro organizace, které chtějí výkonný monitorovací systém bez vysokých poplatků za používání ve stylu SaaS.